Single vs First
As a .net developer, you must possess an experience to deal with two popular methods in your applications. They are SingleOrDefault() and FirstOrDefault(). They are very similar. Both return an object from data set or null value if the object does not exist in data set. But SingleOrDefault has an additional characteristic, it throws an exception when the data set contains the target object more than one. Technically, if you ensure your target object is unique in your data set, you can either use SingleOrDefault() or FirstOrDefault(). It produces the same outcome. However, their performance is different. The performance of SingleOrDefault method is slightly slow than FirstOrDefault. When the size of data set grows larger, the performance of using SingleOrDefault function to find the object, which in the top position in data set, would get slower and slower. It's because the SingleOrDefault function must go through the entire data set even if the target object is located in the top position in the data set. The reason of this stupid logic that is to ensure the target object is unique in data set. That's why SingleOrDefault can throw an exception when the target object is more that one in data set. In contrast, the FirstOrDefault function will exist the function and return the target object immediately when it is found in the data set. Therefore, the performance is better. In order to show you the difference, I create a testing program to test them. This program compares the performance of SingleOrDefault and FirstOrDefault and coded in C# 10. Furthermore, I use a Bogus library to generate dummy testing objects, and I also use the BenchmarkDotNet library to compute the performance.
Implementation Detail
At the beginning of coding, please download the Bogus Library and BenchmarkDotNet from nuget after you create the console project.


Then, Creating a class called Guest before you use the Bogus library to generate a list of dummy object. The class definition shows as follow.
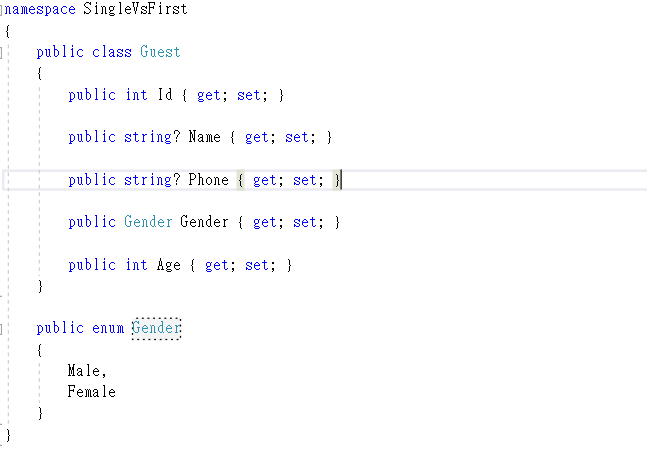
After you created a Guest class, it's time to create a mock up data set through Bogus. For simplicity, I create a simple service class called QueryService. It contains the mock up data set and implement some functions to retrieve the object through FirstOrDefault and SignleOrDefault methods. The class definition shows as follow.
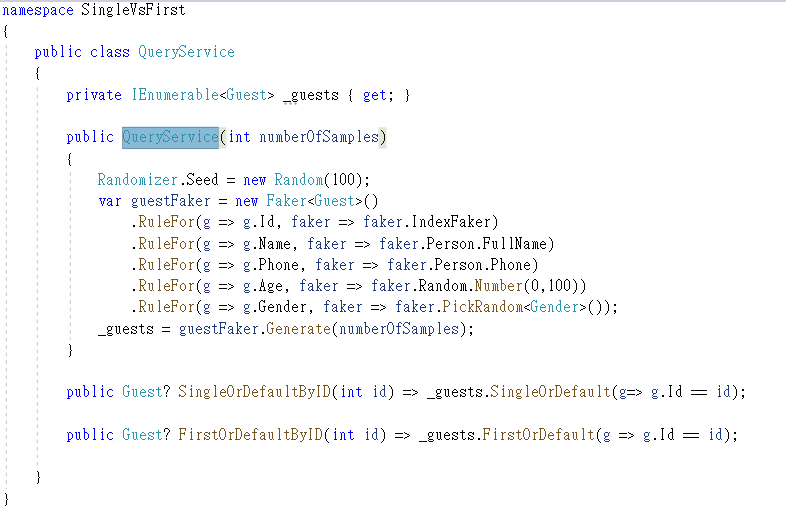
In the constructor, I use the Faker class, which is implemented in the Bogus Library. This class can easily to generate bulk of dummy object with specified condition. There are 5 fields must be generated through Faker Class in this program.
The first is the ID. It is a unique value in dataset obviously. Therefore, I use the IndexFaker to generate them. The IndexFaker assigns the current index of a faker to the generated object, the index is incremented.
The second and third fields are generated through Person which is implemented in Faker too. This let the name and phone of the testing object to be more realistic instead of generating meaningless names and numbers.
The fourth field is generated by faker random number. You can specify the range of the random number. In this example, I restrict the range to [0,100].
The last field is Gender. This is an enum value. For simplicity, I originally intend to use char or string as the type of Gender. But the faker only supports generate a random gender in enum type. That's why I define a Enum called Gender inside the Guest.cs file. The PickRandom method of Faker can randomly pick the enum value so that the random gender can be achieved. The last line code insider the constructor uses the Generate method of Faker to generate bulk of dummy object. The target number is passed by the constructor parameter.
Finally in the QueryService class, I define two method to retrieve the Guest object by ID differently in order to show the performance of SingleOrDefault and FirstOrDefault. They are SingleOrDefaultByID and FirstOrDefaultByID.
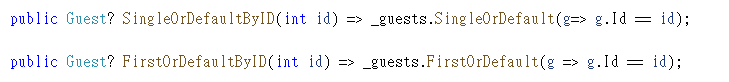
Now, the coding of QueryService is completed. But in order to compare the performance of SingleOrDefault and FirstOrDefault, a comparison methods must be implemented. I use the BenchmarkDotNet to implement the comparison and show the summary. This library is a famous library of C# to do Benchmark testings. Followed the official example, developers must create a class to contains the benchmark function in order to use this library.
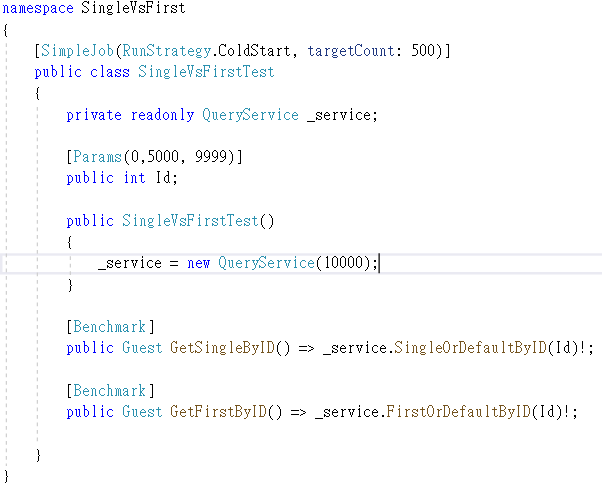
Inside this class, I define a property call id to pass to the test method, which are GetSingleByID and GetFirstByID to find the matching guest. In order to monitor and summarize the performance of test methods, Benchmark attribute must be attached to GetSingleByID and GetFirstByID method. In addition, at the header of the class definition, an attribute tag call SimpleJob is attached. This tag tells the BenchmarkDotNet engine to choose the job type and strategy type. For more detail, please read the official website of BenchmarkDotNet.
Now, back to the program.cs file, and use the following code to invoke the benchmark operation.

Result
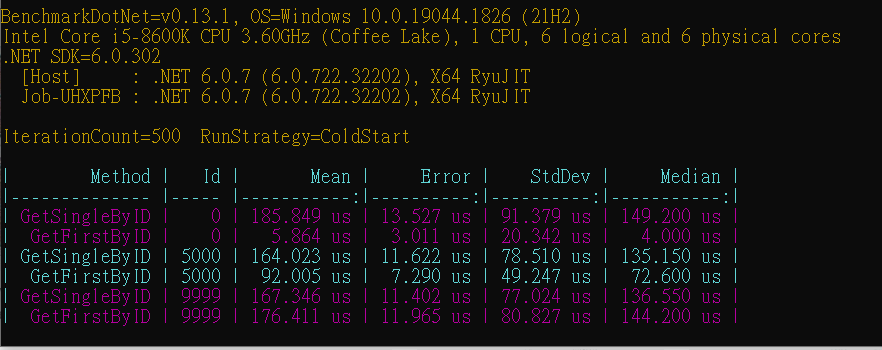
As the result shows, the performance of FirstOrDefault is better than SingleOrDefault when getting the object, which located in the top position or in the middle position in data set. It matches with the expectation. Interestingly, when the target object is in almost the last position, the speed of SingleOrDefault and the speed of FirstOrDefault get closer or even SingleOrDefault is faster. The reason causes this result that because FirstOrDefault method have to check the return condition on each step, but the SingleOrDefault does not. SingleOrDefault will eventually go through the entire data set. Therefore, when the target object is in the last position and the data set is large, the performance is slightly worse than SingleOrDefault.
Wrap-up
In this article, I explain the performance of SingleOrDefault and FirstOrDefault is different even if they will return the single target object. For the sake of getting the exact target object from dataset. I think FirstOrDefault is better in terms of speed. Although the SingleOrDefault ensures that the target object query from the data set is unique. Otherwise, it throws an exception. But it sacrifices the speed. Therefore, I think developer can use other way to guard the object in the dataset is unique rather than dependent on using SingleOrDefault as a safeguard.
As always, thank you for your reading. All the source code of this article can be downloaded in my GitHub.
Please leave your email below.